Trusted by industry leaders



Pretrained models, ready to compose
Chain abilities into Composable Pops that run detection, pose, OCR, tracking, license plate reading, and visual intelligence in a single real-time pass.
Object Detection
Detect people, vehicles, animals, and 50+ object types. Add custom categories without retraining.
Person and Pose
2D and 3D keypoints, face mesh, expression, hand tracking, segmentation, and re-identification in one pipeline.
Text and OCR
Detect and read text in any scene. Landscape and square OCR models optimized for edge deployments.
Tracking
Maintain object identity across frames with persistent tracking. No custom tracking code needed.
License Plate Reading
Detect and decode license plates in real time. Optimized for robotics, parking, and traffic inspection with EyePop's edge-native OCR models.
Visual Intelligence
Prompt-based scene understanding. Ask open-ended questions about what the camera sees: spatial context, object relationships, and scene intent, all in real time.
Deploy on the hardware you already have
EyePop runs on GPU-accelerated edge devices, mobile robotics platforms, on-premise servers, and lightweight CPU-only systems. When you need to scale beyond local hardware, seamlessly offload to the cloud over traditional networking, cellular, or Starlink.

NVIDIA Jetson Orin
GPU-accelerated edge AI for robotics and autonomous vehicles. Runs CUDA-optimized EyePop workers with full ONNX Runtime CUDA EP support on SM 87.

Snapdragon Dragon Wing
Qualcomm NPU-optimized inference for mobile robotics and drones. Low-power, high-throughput vision on the edge with EyePop's ARM-native workers.

NVIDIA GPU Servers
High-throughput on-premise vision servers. Run multiple concurrent pipelines with full GPU acceleration. Ideal for fixed-mount industrial vision.

CPU-Based Systems
x86 and ARM devices with no GPU required. Lightweight models like eyepop.text.recognize.landscape-tiny:latest keep inference fast on constrained hardware.
Cloud & Hybrid Offload
When local hardware can't keep up, seamlessly offload inference to EyePop's cloud over traditional networking, cellular, or Starlink. Same Pop definition, no code changes required.
How composable Pops work
Define your Pop
Choose abilities from the model library: object detection, pose estimation, OCR, segmentation, and more. Combine as many as your task requires.
Create a Smart Workflow of Models
Link models together so each one refines the last. Detect a person, then zoom into just their face for expression or re-ID. All running on-device in a single pass, no cloud required.
Deploy to hardware
Run the same Pop definition on Orin, Snapdragon, NVIDIA GPU servers, or any CPU-based device. No code changes required between targets.
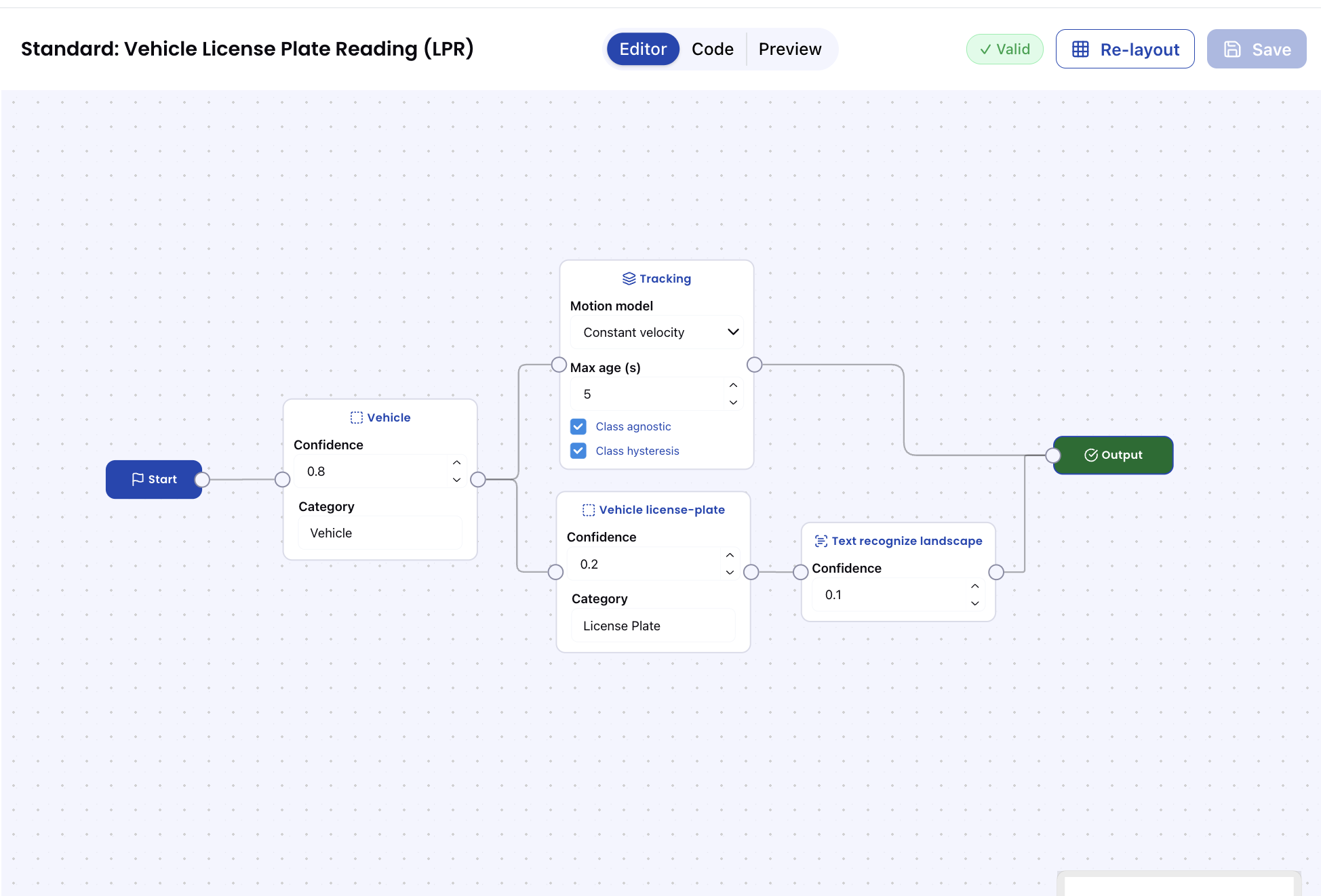
pop = {
"components": [{
"inferenceTypes": ["object_detection"],
"ability": "eyepop.vehicle:latest",
"categoryName": "Vehicle",
"confidenceThreshold": 0.8,
"forward": {
"targets": [{
"type": "tracking",
"maxAgeSeconds": 5,
"agnostic": true,
"motionModel": "constant_velocity",
"classHysteresis": true
},
{
"type": "inference",
"inferenceTypes"["object_detection"],
"ability": "eyepop.vehicle.license-plate:latest",
"categoryName": "License Plate",
"confidenceThreshold": 0.2,
"forward": {
"targets": [{
"type": "inference",
"inferenceTypes": ["ocr"],
"ability": "eyepop.text.recognize.landscape:latest",
"confidenceThreshold": 0.1
}],
"operator": {"type": "crop"}
}
}],
"operator": {"type": "crop"}
}
}]
}Vision AI built for the real world
Real deployments aren't controlled environments. EyePop is engineered for the conditions your hardware actually faces.
First-Person & Egocentric Vision
Whether mounted on a drone nose, a robot gripper, or a wearable, EyePop processes first-person camera feeds at real-time speed with no special pipeline changes required.
Edge-Condition Reliability
Low light, partial occlusions, motion blur, and cluttered industrial scenes. EyePop models are tested and optimized for the messy reality of field and factory deployments.
Beyond Bounding Boxes
Ask open-ended questions about what the camera sees. Spatial context, object relationships, and scene intent: not just where things are, but what is happening.
Your robots get smarter over time
EyePop is built for continuous improvement in the field. Push updated Pops to any device instantly, collect real-world inference results to refine accuracy, and iterate on your vision pipeline without hardware restarts or downtime.
- Push model updates to all deployed devices simultaneously
- Collect field observations to build targeted training sets
- Run A/B comparisons across Pop versions on live hardware
- Fine-tune on domain-specific data without retraining from scratch
Enterprise-grade security
HIPAA-compliant data handling, audit-ready data provenance, and end-to-end encryption. Built for regulated industries including healthcare robotics, industrial automation, and defense.
Start building for Physical AI
Ready to put vision on your device? We'll match the right model stack to your hardware in one call.
Talk to our team